這是在一個不知不覺下完成的一個工作。
做完了才發覺是完成這個動作。
發生的狀況是:
Bee在做不同平台間的移植作業。
來源是68K的系統,目的系統不便明說。
為了方便移植工作順利,先移到Windows平台做模擬驗證動作。
有些和系統及作業系統相關的組合語言,因為在Windows下有另一套函式取代,所以不轉移。
有的則是使用內嵌組合語言的,因為和處理器設定有關的,則是利用條件編譯的方式跳掉。
一路修改所有組合語言相關的程式。直到最後一個...
最後一個函式是atol(),這是標準C的函式庫,但原系統就不用標準C的函式庫,而是用一個手寫函式。
問題是它是100%的組合語言,本想改寫,後來就寫成另一個樣子。
原始函式為:
long atol (const char * Str)
{
asm (" move.l `Str`,a0 ; Address of String");
asm (" move.l d2,-(sp) ; Save D2");
asm (" moveq #0,d0 ; Initialize sum to 0 in D0");
asm (" moveq.l #0,d1");
asm (" moveq #0,d2 ; Assume positive number");
asm (" move.l d0,a1");
asm ("white:");
asm (" move.b (a0)+,d1 ; Get one char into D1");
asm (" cmpi.l #32,d1 ; Skip leading white spaces");
asm (" beq white");
asm (" cmpi.l #13,d1 ; White space include HT,LF,VT,FF,CR");
asm (" bgt.s sign");
asm (" cmpi.l #9,d1 ; Is it >= tab ?");
asm (" bge white");
asm ("sign:");
asm (" cmpi.l #43,d1 ; Is there a (+) sign ?");
asm (" beq.s nextc ; Skip to the next char");
asm (" cmpi.l #45,d1 ; Is it negative ?");
asm (" bne.s digit ; No, start to check for digits");
asm (" moveq #1,d2 ; Remember the number is negative");
asm ("nextc:");
asm (" move.b (a0)+,d1 ; Get next char");
asm ("digit: ; Find the first non-zero digit");
asm (" subi.l #48,d1 ; Integer value of this digit");
asm (" beq nextc ; Skip leading zeros");
asm (" bcs.s return ; Value is 0, return");
asm (" cmpi.l #9,d1 ; Test for valid digits");
asm (" bgt.s return ; Value is 0, return");
asm ("loop:");
asm (" add.l d1,d0 ; Add value of this digit to sum");
asm (" move.b (a0)+,d1 ; Next char");
asm (" subi.l #48,d1 ; Integer value of this digit");
asm (" bcs.s done ; No more digits");
asm (" cmpi.l #9,d1 ; Test for valid digits");
asm (" bgt.s done");
asm (" ; multiply value in D0 by 10 using shifts and add");
asm (" add.l d0,d0 ; Sum * 2");
asm (" move.l d0,a1 ; Save a copy in A1");
asm (" lsl.l #2,d0 ; Sum * 8");
asm (" add.l a1,d0 ; Sum * 10");
asm (" bra loop");
asm ("done:");
asm (" tst.b d2 ; Is the number negative ?");
asm (" beq.s return");
asm (" neg.l d0");
asm ("return:");
asm (" move.l (sp)+,d2 ; Restore D2");
}
改寫為
long atol (const char * Str)
{
register char *a0=(char *)Str;
register long d2=0;
register int d0=0;
register int d1=0;
register int a1=0;
White:
d1 = *a0++;
if( d1 == ' ') goto White;
if( d1 > 13 ) goto Sign;
if( d1 >= 9 ) goto White;
Sign:
if( d1 == 43 ) goto Nextc;
if( d1 != 45 ) goto Digit;
d2 = 1;
Nextc:
d1 = *a0++;
Digit:
d1 -= 48;
if( d1 == 0) goto Nextc;
if( d1 < 0 ) goto Return;
if( d1 > 9 ) goto Return;
Loop:
d0 += d1;
d1 = *a0++;
d1 -= 48;
if( d1 < 0 ) goto Done;
if( d1 > 9 ) goto Done;
d0 += d0;
a1 = d0;
d0 = d0 << 2;
d0 += a1;
goto Loop;
Done:
if( d2 == 0 ) goto Return;
d0 = -d0;
Return:
return d0;
}
這是新改函式產生出來的組合語言檔
XDEF _atol
?type 260,x,'atol',0,1,14336,20,1,259,0
?f_x_d 'atol',12,260
_atol:
?v_a_d 'Str',4,259
?v_l_d 'a0',0,a0,261
?v_l_d 'd2',0,d1,20
?v_l_d 'd0',0,d3,16
?v_l_d 'd1',0,d2,16
?v_l_d 'a1',0,d4,16
?line 21,30
lea.l -12(sp),sp
movem.l d2/d3/d4,(sp)
moveq #0,d0
?line 74,33
movea.l 16(sp),a0
?line 75,23
moveq #0,d1
?line 76,23
moveq #0,d3
?line 77,23
moveq #0,d2
?line 78,23
moveq #0,d4
?line 80,14
L1:
move.b (a0)+,d2
extb.l d2
?line 81,17
moveq #32,d0
cmp.l d2,d0
beq.s L1
?line 82,15
moveq #13,d0
cmp.l d2,d0
blt.s L4
?line 83,15
moveq #9,d0
cmp.l d2,d0
ble.s L1
?line 85,16
L4:
moveq #43,d0
cmp.l d2,d0
beq.s L7
?line 86,16
moveq #45,d0
cmp.l d2,d0
bne.s L9
?line 87,10
moveq #1,d1
?line 89,14
L7:
move.b (a0)+,d2
extb.l d2
?line 91,12
L9:
moveq #-48,d0
add.l d0,d2
?line 92,15
beq.s L7
?line 93,14
tst.l d2
bmi.s L12
?line 94,14
moveq #9,d0
cmp.l d2,d0
blt.s L12
?line 96,12
L14:
add.l d2,d3
?line 97,14
move.b (a0)+,d2
extb.l d2
?line 98,12
moveq #-48,d0
add.l d0,d2
?line 99,14
bmi.s L16
?line 100,14
moveq #9,d0
cmp.l d2,d0
blt.s L16
?line 101,12
add.l d3,d3
?line 102,11
move.l d3,d4
?line 103,16
lsl.l #2,d3
?line 104,12
add.l d4,d3
?line 105,13
bra.s L14
?line 107,15
L16:
tst.l d1
beq.s L12
?line 108,12
neg.l d3
?line 110,13
L12:
move.l d3,d0
?line 111,1
movem.l (sp),d2/d3/d4
lea.l 12(sp),sp
rts
; code: 124 bytes stack: 12 bytes
?end
經比對轉出的組合語言動作符合。然後也可以在Windows系統下順利編譯。
寫完後無聊,用Google找找看有沒有組合語言轉成C語言相關的事。
所得答案是:沒有這種方法。
可是Bee完成了這樣的事!
而且在寫的過程中發現轉換的方法。
大部分組合語言可以轉成單行的C語言。
Bee不去處理程式結構的轉換,所以只要把標記(Label)直接轉成C的標記。
無條件跳越直接可以翻成 goto Label;
比較有問題的是程式控制指令。
做法很簡單,就直接轉成 if() goto Label;
唯一要處理的是if括號內的東西。
括號內的,和上一個指令有關。
上個指令是比較指令,就直接移進括號內。
上個指令不是比較指令,就將有影響的暫存器放入括號內。
一路就做完了,也沒有問題。
沒想到就這樣完成了一個網路找不到答案的問題。
只是確保可以動作,但效率不好。
可以看看翻出來的組合語言,多出了許多動作。
好在只是在Windows上模擬,先可以過再說。還有一堆的問題還要解決啊!
2010年12月1日 星期三
OpenCV2.1+CUDA 64位元整合:結果失敗
最近Bee換筆記電腦是具有GeForce GT 420M的顯示卡。
現在都是安裝Windows 7 x64的版本。故Bee下載CUDA 64位元回來安裝。
到這裡都沒有問題。只有CUDA 64部分設定要自己手工調整。
之後有許多工具都很不習慣,花了不少時間去找。整個Windows和XP實在差太多了。
另外有一些其他奇怪的地方有些程式找不到裝置,原來還有UAC的問題。
好吧!看在64位元可以不受4GB限制,還是去適應好了 。
弄了數週,才想到回來看看CUDA程式。
結果,CUDA 64無法和Win32的OpenCV做Link。
而OpenCV沒有64位元的Library。那只好自己編函式庫了。
奇怪的是OpenCV2.1明明就有寫支援64位元,但一直編不出可以用的函式庫。
查過在其他平台都是可以用的。但在VS2008及VS2010就有問題。
沒錯!就是這個問題。但....沒有人解成功。
Bee又安裝了好幾次,沒一次成。查了很久,發現是沒有載入該有的函式庫。
為何!M$的C++老是玩這種,每次編出來的程式都很難搬。
最後沒辦法,回去Win32。安裝CUDA 32然後Link OpenCV,就過了。
再等OpenCV下一版再看看。
不過64位元整合算是失敗了。看來時代還沒有到。
還有很多應用軟體也都是在Win32模式下,沒有幾套是64位元。
要換到64位元,看來還是不容易取得優勢。反而是環境大改,真是不習慣。
現在都是安裝Windows 7 x64的版本。故Bee下載CUDA 64位元回來安裝。
到這裡都沒有問題。只有CUDA 64部分設定要自己手工調整。
之後有許多工具都很不習慣,花了不少時間去找。整個Windows和XP實在差太多了。
另外有一些其他奇怪的地方有些程式找不到裝置,原來還有UAC的問題。
好吧!看在64位元可以不受4GB限制,還是去適應好了 。
弄了數週,才想到回來看看CUDA程式。
結果,CUDA 64無法和Win32的OpenCV做Link。
而OpenCV沒有64位元的Library。那只好自己編函式庫了。
奇怪的是OpenCV2.1明明就有寫支援64位元,但一直編不出可以用的函式庫。
查過在其他平台都是可以用的。但在VS2008及VS2010就有問題。
沒錯!就是這個問題。但....沒有人解成功。
Bee又安裝了好幾次,沒一次成。查了很久,發現是沒有載入該有的函式庫。
為何!M$的C++老是玩這種,每次編出來的程式都很難搬。
最後沒辦法,回去Win32。安裝CUDA 32然後Link OpenCV,就過了。
再等OpenCV下一版再看看。
不過64位元整合算是失敗了。看來時代還沒有到。
還有很多應用軟體也都是在Win32模式下,沒有幾套是64位元。
要換到64位元,看來還是不容易取得優勢。反而是環境大改,真是不習慣。
2010年9月30日 星期四
YARP介紹
YARP全名Yet Another Robot Platform為人型機器人發展平台。主要目標是降低人型機器人發展的困難度。
機器人現行軟體發展的問題是,在硬體變化快速的狀況下,若是軟體一直要隨硬體而修改,將使機器人軟體發展不易。
但硬體的改變是必定會遭遇到,所以必須使高層軟體可以重覆利用。另外和硬體相關的程式必須模組化,以便於新硬體加入。
其實也有許多機器人發展平台,但都是綁語言或是綁硬體。YARP則是使用C++語言為基礎,並採用Open Source的開放架構。
另外在跨平台部分,採用CMake來達成不同作業系統平台上的移轉,例如使用同一個程式碼可以編譯成Linux,Windows及OS X的執行檔。
YARP設計為一層Middleware,所以可以使用其他語言來觸發。可以用一般Shell上發動的語言例如:Java、Perl、Python及TCL等。Matlab則可以利用Java做為界面觸發。
Bee看了一下YARP是如何達成如此多的語言可以連接,其實很簡單,就是將裝置做成檔案夾的方式。這個是Unix常用的模式,所以可以容易去連接。
而為了將同類裝置使用相同高階程式,則必項將不同啟動程式設定在像.ini檔案中,內容以XML做為描述語言。
對Bee來說有幾個地方是有興趣的。最重要的是在應用上,可以做為分散式嵌入式系統的發展平台,可以讓不同的機器統合而完成一個工作。
而且也有幾個模組也是Bee感興趣的,其中包括有CUDA、OpenCV、MPI及馬達控制。
看來是值得去研究的架構。
機器人現行軟體發展的問題是,在硬體變化快速的狀況下,若是軟體一直要隨硬體而修改,將使機器人軟體發展不易。
但硬體的改變是必定會遭遇到,所以必須使高層軟體可以重覆利用。另外和硬體相關的程式必須模組化,以便於新硬體加入。
其實也有許多機器人發展平台,但都是綁語言或是綁硬體。YARP則是使用C++語言為基礎,並採用Open Source的開放架構。
另外在跨平台部分,採用CMake來達成不同作業系統平台上的移轉,例如使用同一個程式碼可以編譯成Linux,Windows及OS X的執行檔。
YARP設計為一層Middleware,所以可以使用其他語言來觸發。可以用一般Shell上發動的語言例如:Java、Perl、Python及TCL等。Matlab則可以利用Java做為界面觸發。
Bee看了一下YARP是如何達成如此多的語言可以連接,其實很簡單,就是將裝置做成檔案夾的方式。這個是Unix常用的模式,所以可以容易去連接。
而為了將同類裝置使用相同高階程式,則必項將不同啟動程式設定在像.ini檔案中,內容以XML做為描述語言。
對Bee來說有幾個地方是有興趣的。最重要的是在應用上,可以做為分散式嵌入式系統的發展平台,可以讓不同的機器統合而完成一個工作。
而且也有幾個模組也是Bee感興趣的,其中包括有CUDA、OpenCV、MPI及馬達控制。
看來是值得去研究的架構。
2010年8月24日 星期二
最近CUDA程式上的進展
最新主要是改寫別人的CUDA程式。Open Source前幾版真是Bug百出,想找要好改的還要各方比較。
改寫除了解Bug外,也有一些問題要解決。
1.資源調度
最常拿到的是CUDA硬體1.3版的程式,剛好Bee又想用筆電跑,就要改成硬體1.1版。
這種狀況就要會做資源調度的程式改寫了。
2.改C++程式
Bee是C的使用者,C++不熟。不過遇到的算是原本CPU程式轉成CUDA之後造成的問題。
今天抓一個CUDA記憶體取用爆炸問題。追出來問題是長這樣:
原先使用物件只有建構函式,改寫為CUDA時,要在建構函式中取用CUDA記憶體,將資料轉到CUDA去。
後面也有其他函式使用CUDA上的資料運算。
處理單張照片時沒事,放到Webcam執行時,就產生記憶體不足。Bee也感到奇怪,1G的記憶體不夠用。
拿GPU-Z來看,真的用了1G。主要是每次處理照片,就會多出一些記憶體,是累積到爆的。
看程式還看不出問題,後來才發現,原來是建構時取用的CUDA記憶體沒釋放。
因為C++在物件使用完畢後,會自己釋放掉記憶體,所以很多人不寫解構函式。
可是改寫CUDA時,一樣在建構時取用CUDA的記憶體,自動解構時只會釋放CPU側。
而且相關的指標會釋放,在CUDA取用內的記憶體就變成沒人管的記憶體。
Bee加入解構,其內釋放CUDA記憶體,就這樣解決了。
CUDA還是用C的記憶體操作,不會自動回收。直接使用C++程式移植來的,這點還是要注意。
改寫除了解Bug外,也有一些問題要解決。
1.資源調度
最常拿到的是CUDA硬體1.3版的程式,剛好Bee又想用筆電跑,就要改成硬體1.1版。
這種狀況就要會做資源調度的程式改寫了。
2.改C++程式
Bee是C的使用者,C++不熟。不過遇到的算是原本CPU程式轉成CUDA之後造成的問題。
今天抓一個CUDA記憶體取用爆炸問題。追出來問題是長這樣:
原先使用物件只有建構函式,改寫為CUDA時,要在建構函式中取用CUDA記憶體,將資料轉到CUDA去。
後面也有其他函式使用CUDA上的資料運算。
處理單張照片時沒事,放到Webcam執行時,就產生記憶體不足。Bee也感到奇怪,1G的記憶體不夠用。
拿GPU-Z來看,真的用了1G。主要是每次處理照片,就會多出一些記憶體,是累積到爆的。
看程式還看不出問題,後來才發現,原來是建構時取用的CUDA記憶體沒釋放。
因為C++在物件使用完畢後,會自己釋放掉記憶體,所以很多人不寫解構函式。
可是改寫CUDA時,一樣在建構時取用CUDA的記憶體,自動解構時只會釋放CPU側。
而且相關的指標會釋放,在CUDA取用內的記憶體就變成沒人管的記憶體。
Bee加入解構,其內釋放CUDA記憶體,就這樣解決了。
CUDA還是用C的記憶體操作,不會自動回收。直接使用C++程式移植來的,這點還是要注意。
2010年8月17日 星期二
新寵物:蚯蚓
家中的寵物有二隻貓、二隻鳥以及一隻兔子。
最近Bee則買了蚯蚓來養。
一定會有人問,已有這麼多動物,為何要養蚯蚓?
因為Bee的如意算盤是:利用兔子糞養蚯蚓,產生有機土。若是蚯蚓過剩,則變成鳥的點心。
而貓糞則可能含有可傳染人的病源,所以不予利用。
結果進行了一個月,終於進行到投餵兔子糞的階段了。為何搞了一個月,就看以下報告了。
當初要養蚯蚓,也有想要將廚餘轉成堆肥。所以養殖箱和蚯蚓一到,馬上將家中廚餘全倒進養殖箱中裝滿。
這是錯的!後面災難就來了。
晚上蚯蚓大逃亡,結果白天就要揀蚯蚓。這才發現蚯蚓不喜臭味。
解決方法是加入新土,看看是不是增加活動空間可以解。
這招有點用,但箱子八分以上滿。不太能再放東西了。
接下來,另一個災難出現了,長了一堆蛆。
Bee不想養蠅蛆,因為它不會產生土壤。而且搶食能力大於蚯蚓,養料都被蛆吃掉了。
然後每天晚上帶著手電筒及筷子去夾蛆丟棄。
一個月後,找到了飼養箱製造商,買了新箱子,決定分箱養,順便除掉蛆。
滿箱的土,Bee弄了一下午沒弄完,最後變成三箱。
一箱是使用培養土做為基土,一箱是黏土加培養土,原始的箱子還有剩,就成了第三箱。
剛換土又是一次大逃亡,後來就穩定不逃了。
現在則是每天加料再蓋上新培養土,果然不再長蛆,但在分箱時仍有少量蛆。等長大點再除掉。
新箱中基土少多了,所以開始實驗投入不同種類及重量的食物。
果然開始照Bee的預期可以使用兔子糞了。
最近Bee則買了蚯蚓來養。
一定會有人問,已有這麼多動物,為何要養蚯蚓?
因為Bee的如意算盤是:利用兔子糞養蚯蚓,產生有機土。若是蚯蚓過剩,則變成鳥的點心。
而貓糞則可能含有可傳染人的病源,所以不予利用。
結果進行了一個月,終於進行到投餵兔子糞的階段了。為何搞了一個月,就看以下報告了。
當初要養蚯蚓,也有想要將廚餘轉成堆肥。所以養殖箱和蚯蚓一到,馬上將家中廚餘全倒進養殖箱中裝滿。
這是錯的!後面災難就來了。
晚上蚯蚓大逃亡,結果白天就要揀蚯蚓。這才發現蚯蚓不喜臭味。
解決方法是加入新土,看看是不是增加活動空間可以解。
這招有點用,但箱子八分以上滿。不太能再放東西了。
接下來,另一個災難出現了,長了一堆蛆。
Bee不想養蠅蛆,因為它不會產生土壤。而且搶食能力大於蚯蚓,養料都被蛆吃掉了。
然後每天晚上帶著手電筒及筷子去夾蛆丟棄。
一個月後,找到了飼養箱製造商,買了新箱子,決定分箱養,順便除掉蛆。
滿箱的土,Bee弄了一下午沒弄完,最後變成三箱。
一箱是使用培養土做為基土,一箱是黏土加培養土,原始的箱子還有剩,就成了第三箱。
剛換土又是一次大逃亡,後來就穩定不逃了。
現在則是每天加料再蓋上新培養土,果然不再長蛆,但在分箱時仍有少量蛆。等長大點再除掉。
新箱中基土少多了,所以開始實驗投入不同種類及重量的食物。
果然開始照Bee的預期可以使用兔子糞了。
2010年7月15日 星期四
即時作業系統是如何演進的
在小型MCU上面用的工作排程(Task Schedule)Bee整理了一下。
發現從使用硬體中斷,到即時作業系統(RTOS)之間有演進的程序。
1.Round-Robin:不使用中斷,只使用輪詢方式,做為排程。
2.Foreground/Background:只使用中斷,利用硬體排程。
3.Round-Robin with Interrupt:使用中斷及輪詢混合式排程。
4.Coroutine:將輪詢方式的排程改為經由軟體呼叫方式切換。並加入排程工作鏈,管理工作加入及移除。
5.Real-Time Operating System:現代即時作業系統,函式一下子增加了許多。工作切換可以利用設定事件(Event)方式,設定排程的條件。
前三種及RTOS在uCOS的書中有介紹,但Bee認為奇怪的是為何工作排程一下子變的如此複雜。
在使用中斷管理及現代作業系統之間,一定存在軟體可以管理,但又沒有強制切換的管理系統。
不幸的是,中間型式就像物種進化中的失落環節一樣,幾乎找不到資料。
後來才從Forth語言及Lua語言上找到Coroutine,Bee才確定有Coroutine這型排程管理系統存在。
以下就功能特性做一個比較:
1.Round-Robin:
特性:這是最簡單的排程系統,但時間控制不精準。
Task Control : Pulling
Time Function : Depend on assemble code or instruction delay
Data Exchange : Global variable
State Machine : Run on open loop,state control by data


2.Foreground/Background:
特性:將需要精準時間控制的工作放入中斷。
Task Control : Interrupt
Time Function : In interrupt using counter control function call
Data Exchange : User control with protected global variable
State Machine : Run on open loop,state control by data
 要解決問題:變數保護問題,假設有一個函式如下。
要解決問題:變數保護問題,假設有一個函式如下。
int temp;
void swap( int *x, int *y)
{
temp = *x;
*x = *y;
*y = temp;
}
這個函式若由main()及中斷中都有使用到,則會發生變數衝突問題。這個問題則要由工程師自己注意。

3.Round-Robin with Interrupt:
特性:加入多種工作時,要改成這個結構。
Task Control : Interrupt/Pulling
Time Function : Interrupt Function/Interrupt Flag to Round-Robin Function
Data Exchange : User control with protected global variable/Global Variable
State Machine : Run on open loop,state control by data

4.Coroutine:
特性:加入工作管理,可以加入及移除工作項目
Task Control : O.S. Function/Interrupt
Time Function : Interrupt Function / O.S. Function
Data Exchange : Global Variable
State Machine : Program Structure Control



5.Real-Time Operating System:
特性:現在作業系統功能
Task Control : O.S. Function
Time Function : O.S. Function
Data Exchange : O.S. Function
State Machine : Program Structure Control


發現從使用硬體中斷,到即時作業系統(RTOS)之間有演進的程序。
1.Round-Robin:不使用中斷,只使用輪詢方式,做為排程。
2.Foreground/Background:只使用中斷,利用硬體排程。
3.Round-Robin with Interrupt:使用中斷及輪詢混合式排程。
4.Coroutine:將輪詢方式的排程改為經由軟體呼叫方式切換。並加入排程工作鏈,管理工作加入及移除。
5.Real-Time Operating System:現代即時作業系統,函式一下子增加了許多。工作切換可以利用設定事件(Event)方式,設定排程的條件。
前三種及RTOS在uCOS的書中有介紹,但Bee認為奇怪的是為何工作排程一下子變的如此複雜。
在使用中斷管理及現代作業系統之間,一定存在軟體可以管理,但又沒有強制切換的管理系統。
不幸的是,中間型式就像物種進化中的失落環節一樣,幾乎找不到資料。
後來才從Forth語言及Lua語言上找到Coroutine,Bee才確定有Coroutine這型排程管理系統存在。
以下就功能特性做一個比較:
1.Round-Robin:
特性:這是最簡單的排程系統,但時間控制不精準。
Task Control : Pulling
Time Function : Depend on assemble code or instruction delay
Data Exchange : Global variable
State Machine : Run on open loop,state control by data


2.Foreground/Background:
特性:將需要精準時間控制的工作放入中斷。
Task Control : Interrupt
Time Function : In interrupt using counter control function call
Data Exchange : User control with protected global variable
State Machine : Run on open loop,state control by data

int temp;
void swap( int *x, int *y)
{
temp = *x;
*x = *y;
*y = temp;
}
這個函式若由main()及中斷中都有使用到,則會發生變數衝突問題。這個問題則要由工程師自己注意。

3.Round-Robin with Interrupt:
特性:加入多種工作時,要改成這個結構。
Task Control : Interrupt/Pulling
Time Function : Interrupt Function/Interrupt Flag to Round-Robin Function
Data Exchange : User control with protected global variable/Global Variable
State Machine : Run on open loop,state control by data

4.Coroutine:
特性:加入工作管理,可以加入及移除工作項目
Task Control : O.S. Function/Interrupt
Time Function : Interrupt Function / O.S. Function
Data Exchange : Global Variable
State Machine : Program Structure Control



5.Real-Time Operating System:
特性:現在作業系統功能
Task Control : O.S. Function
Time Function : O.S. Function
Data Exchange : O.S. Function
State Machine : Program Structure Control


2010年7月11日 星期日
過時的工程師
前些時候Bee遇到了一位自製CPU的工程師,今年則是遇到開CPU的工程師。
Bee是曾經想自製CPU,所以要聊CPU可能可以找的人也不多,所以會談到一些市場的問題。
對他們來說,Bee算是自製CPU的逃兵。可是Bee早在數年前就覺得這個領域是不能再待的。因為市場快要過時了。
只是不到十年,就已成真。未來可以遇到的CPU可能不多了。
二個人我都問過一樣的問題:為何不改走別條路。回答的原因很多,但有一個共同的是,已投入十年以上的技術,不能放棄。
不過技術本來就會過時,科技業本就是如此!即使學有專精,還是有過時的一天。
但舊技術是不會消失,只是看人如何去用,如何加入新元素,找到新市場。
不過可以肯定的是,硬體為主的時代已過,現在走的是軟體服務時代。
現代軟體工程師也和以前不同,以前的軟體工程師會熟讀原始碼才使用,甚至改寫。現代的則是找Open Source直接用。
有些軟體開發環境已經和以前不同了。網路發達是主因,但軟體環境也變了許多。
除錯工具的精進,也改變了寫程式的生態。
有許多的函式庫可以用,不用再去做非常深入的了解。
不同時代,環境不同,所以生存機制不同。藉由以往成功的經驗是不一定能在新的環境下成功。
而且使用不對,反而會走向失敗。
人生沒有幾個十年,要如何走才是要好好考量的。
Bee是曾經想自製CPU,所以要聊CPU可能可以找的人也不多,所以會談到一些市場的問題。
對他們來說,Bee算是自製CPU的逃兵。可是Bee早在數年前就覺得這個領域是不能再待的。因為市場快要過時了。
只是不到十年,就已成真。未來可以遇到的CPU可能不多了。
二個人我都問過一樣的問題:為何不改走別條路。回答的原因很多,但有一個共同的是,已投入十年以上的技術,不能放棄。
不過技術本來就會過時,科技業本就是如此!即使學有專精,還是有過時的一天。
但舊技術是不會消失,只是看人如何去用,如何加入新元素,找到新市場。
不過可以肯定的是,硬體為主的時代已過,現在走的是軟體服務時代。
現代軟體工程師也和以前不同,以前的軟體工程師會熟讀原始碼才使用,甚至改寫。現代的則是找Open Source直接用。
有些軟體開發環境已經和以前不同了。網路發達是主因,但軟體環境也變了許多。
除錯工具的精進,也改變了寫程式的生態。
有許多的函式庫可以用,不用再去做非常深入的了解。
不同時代,環境不同,所以生存機制不同。藉由以往成功的經驗是不一定能在新的環境下成功。
而且使用不對,反而會走向失敗。
人生沒有幾個十年,要如何走才是要好好考量的。
2010年6月25日 星期五
用PC控制史賓機器人
這是Bee讀研究所科目之大作。因為做起來要打通的東西還真不少。
其實也是Bee當時重要研究所的夢想實現。
就概念上很簡單,就是希望可以寫程式遙控機器人動作。
機器人要重做很麻煩且沒有時間,因為這只是單一科目之專題。
所以找到"史賓機器人"。

這是它的遙控器

剛好又找到遙控器相關資料。很多已經失去連接了,目前可以找到的為
史賓機器人紅外線碼
實際量測結果無誤,所以我便規劃重製遙控器來做到遙控。

不過實現上最關鍵的是USB遙控器,主因是現行筆電已經沒有RS232可以用了。
在這方面則是採用Silicon Lab的C8051F340這個單晶片來解決。

所以整個系統架構為

使用單晶片不是問題,但Bee使用過各式怪單晶片,這次終於用到8051了,不過這是不是值得高興的事。
單晶片上手對Bee來說容易,倒是去除錯別人的系統,要花功夫了。
另外這也是第一次開發DLL給PC應用端程式。

之所以不使用單一應用程式,主要是測試靈活度,故採用Win32Forth做為PC端測試界面,另一方面寫出來的是中文的程式哦!

Bee記得一星期就做完了,其中確認推動信號強度不足就花了一天。
第一階段,將硬體及8051程式建造完畢。
第二階段,做DLL程式,因為這是第一次做,所以花的比較久。BCB 6和VC參數傳遞上有些定義差異花了許多時間。
第三階段,做系統串連測試,確認是無法動作。後來才查出是推動信號強度不足。所以又改了一下電路。

一做完,就先去FIG去展示,那時報告都還沒有寫。所以寫了點草稿就去報告了。
後來開學後修了uCOS-II的課,就把整個系統拿來做專題,重新改寫8051的部分,將uCOS-II放進去。
之所以是大作,其實是先在暑假就做完,上課才硬是把它轉成專題拿去交。比起上課後才想專題,自然做得更完備。
其實也是Bee當時重要研究所的夢想實現。
就概念上很簡單,就是希望可以寫程式遙控機器人動作。
機器人要重做很麻煩且沒有時間,因為這只是單一科目之專題。
所以找到"史賓機器人"。

這是它的遙控器

剛好又找到遙控器相關資料。很多已經失去連接了,目前可以找到的為
史賓機器人紅外線碼
實際量測結果無誤,所以我便規劃重製遙控器來做到遙控。

不過實現上最關鍵的是USB遙控器,主因是現行筆電已經沒有RS232可以用了。
在這方面則是採用Silicon Lab的C8051F340這個單晶片來解決。

所以整個系統架構為

使用單晶片不是問題,但Bee使用過各式怪單晶片,這次終於用到8051了,不過這是不是值得高興的事。
單晶片上手對Bee來說容易,倒是去除錯別人的系統,要花功夫了。
另外這也是第一次開發DLL給PC應用端程式。

之所以不使用單一應用程式,主要是測試靈活度,故採用Win32Forth做為PC端測試界面,另一方面寫出來的是中文的程式哦!

Bee記得一星期就做完了,其中確認推動信號強度不足就花了一天。
第一階段,將硬體及8051程式建造完畢。
第二階段,做DLL程式,因為這是第一次做,所以花的比較久。BCB 6和VC參數傳遞上有些定義差異花了許多時間。
第三階段,做系統串連測試,確認是無法動作。後來才查出是推動信號強度不足。所以又改了一下電路。

一做完,就先去FIG去展示,那時報告都還沒有寫。所以寫了點草稿就去報告了。
後來開學後修了uCOS-II的課,就把整個系統拿來做專題,重新改寫8051的部分,將uCOS-II放進去。
之所以是大作,其實是先在暑假就做完,上課才硬是把它轉成專題拿去交。比起上課後才想專題,自然做得更完備。
2010年5月25日 星期二
測試DLL函式庫功能
這是Bee最常用的。拿來測試DLL內的功能並看單一結果。
在Win32Forth下直接寫以下程式,去連接OpenCV的DLL並呼叫函式
WinLibrary cv110.dll
WinLibrary cxcore110.dll
WinLibrary highgui110.dll
1 z" Win32Forth Call CV DLL " call cvNamedWindow
結果就有一個視窗出現,標題字串就是由Win32Forth傳的。

但有一些規則還是要注意(其實是Bee太久沒用,寫給自己做記錄):
1. 參數要查出真值,因為無法使用C的#include。
2. 參數要倒序先放,這是Win32Forth的習慣。
3. 字串使用 z",因為Forth的字串和C的格式不同。
在Win32Forth下直接寫以下程式,去連接OpenCV的DLL並呼叫函式
WinLibrary cv110.dll
WinLibrary cxcore110.dll
WinLibrary highgui110.dll
1 z" Win32Forth Call CV DLL " call cvNamedWindow
結果就有一個視窗出現,標題字串就是由Win32Forth傳的。
但有一些規則還是要注意(其實是Bee太久沒用,寫給自己做記錄):
1. 參數要查出真值,因為無法使用C的#include。
2. 參數要倒序先放,這是Win32Forth的習慣。
3. 字串使用 z",因為Forth的字串和C的格式不同。
2010年5月17日 星期一
近二個月電腦語言排名變動大
繼上個月排名第一的換了,這個月排名十也換了。
不過排名十附近的"三軍"本來就不是那麼穩定。
比較令Bee在意的是Basic,已經確定離開二軍靠到三軍去了。
一但和三軍在一起,和許多具不同特性的語言"拼",很難再佔有絕對優勢的。
不過VB和C#確定是要正面交鋒了。這下VB可能更是不被看好,因為雖是同父母,喜好程度大不同。
不過排名三十最近變動也大,不知是什麼狀況。

看著看著才發現,怎麼都是C在抬頭。C、C++、C#、Objective-C,都有C。
不過排名十附近的"三軍"本來就不是那麼穩定。
比較令Bee在意的是Basic,已經確定離開二軍靠到三軍去了。
一但和三軍在一起,和許多具不同特性的語言"拼",很難再佔有絕對優勢的。
不過VB和C#確定是要正面交鋒了。這下VB可能更是不被看好,因為雖是同父母,喜好程度大不同。
不過排名三十最近變動也大,不知是什麼狀況。

看著看著才發現,怎麼都是C在抬頭。C、C++、C#、Objective-C,都有C。
2010年5月14日 星期五
重做uCOS-II Win32 port的心得
發現竟然又懂得更多。
因為移植了幾個程式,跑起來還是有點小問題,一一修正後,可以修正到我想要的結果。
但不同的不台,要加入不同的驅動方法。
像取用亂數這件事rand()。
在uCOS-II中,被視為共用資源,所以要保護起來。
但在Win32中有無保護都沒有影響。
現在才發現原來Win32已保護過了,所以一點影響也沒有。
但好玩的是每一個Task都有一樣序列的亂數。
那是因為在Win32,每一個Thread皆有自己的區域變數,rand()就是其一。
後來各task使用自己的srand(),利用windows的時間計數器為種子。
結果10個task只有分成二群,大概是使用雙核心的結果。
那在各task創造時加入不同的延時,果真創造出10個使用不同亂數序列的Task。
二年前還不了解的狀況,如今一下子就解開了。
試驗程式:
有十個Task,各自擁有唯一數字0~9,隨機找位置填入。
也就是擁有"0"的一直找地方填。其他Task也相同。
這是原始的程式結果,為MSDOS程式。

Win32模擬成功後的樣子。
發現所有Task皆使用一樣的亂數序列的狀況

這是加了使用系統時間做為亂數種子的結果,只有分成二群。

修改過最後結果。

因為移植了幾個程式,跑起來還是有點小問題,一一修正後,可以修正到我想要的結果。
但不同的不台,要加入不同的驅動方法。
像取用亂數這件事rand()。
在uCOS-II中,被視為共用資源,所以要保護起來。
但在Win32中有無保護都沒有影響。
現在才發現原來Win32已保護過了,所以一點影響也沒有。
但好玩的是每一個Task都有一樣序列的亂數。
那是因為在Win32,每一個Thread皆有自己的區域變數,rand()就是其一。
後來各task使用自己的srand(),利用windows的時間計數器為種子。
結果10個task只有分成二群,大概是使用雙核心的結果。
那在各task創造時加入不同的延時,果真創造出10個使用不同亂數序列的Task。
二年前還不了解的狀況,如今一下子就解開了。
試驗程式:
有十個Task,各自擁有唯一數字0~9,隨機找位置填入。
也就是擁有"0"的一直找地方填。其他Task也相同。
這是原始的程式結果,為MSDOS程式。

Win32模擬成功後的樣子。
發現所有Task皆使用一樣的亂數序列的狀況

這是加了使用系統時間做為亂數種子的結果,只有分成二群。

修改過最後結果。

2010年5月12日 星期三
讀書:精通Windows API
看這本書是因為Bee要學Windows程式,實際的說法是,利用Windows作業系統。
因為Bee是C語言使用者,還是喜歡Console系統,但還是需要使用Windows資源才找此書。
主要是要解決uCOS-II win32 port資源利用問題。
不過Windows API查是查得到,但有許多部分沒有說明系統模型及使用方式。
還是找書還比較好,有系統環境說明。另外還有開發環境的說明。
其他像視窗程式,我是覺得還是放個console做為除錯也沒差。反正有方法關掉,使用Editbin去編譯exe檔的屬性的行了。
另外像是cuda也只能使用main()做為進入點,所以還是不用去轉換進入點的形式。
接下來應該就是配合uCOS-II一起玩了。

因為Bee是C語言使用者,還是喜歡Console系統,但還是需要使用Windows資源才找此書。
主要是要解決uCOS-II win32 port資源利用問題。
不過Windows API查是查得到,但有許多部分沒有說明系統模型及使用方式。
還是找書還比較好,有系統環境說明。另外還有開發環境的說明。
其他像視窗程式,我是覺得還是放個console做為除錯也沒差。反正有方法關掉,使用Editbin去編譯exe檔的屬性的行了。
另外像是cuda也只能使用main()做為進入點,所以還是不用去轉換進入點的形式。
接下來應該就是配合uCOS-II一起玩了。

2010年5月10日 星期一
讀書:程式設計師的自我修養─連接、載入、程式庫
這本書,光是標題,許多人連看也不會看。基本上這些工作都是作業系統做完了。
但寫程式,每天都在用,卻沒有什麼人想了解。
可是在嵌入式系統,這是基本功,基本到被人忽略。
所以Bee可以了解到這本書名為何要取名為程式設計師的自我修養。
書上的系統是以PC作業系統為平台。不過我本來沒有多大興趣,結果一看就停不下來。
Bee沒有想到有書如此詳細解析Loader,library,DLL的格式,還可以修改。
其中在Linux的資料特別詳細,也難怪嵌入式系統使用PC幾乎只用Linux。
因為Windows上什麼也不公開。而嵌入式的環境又是如此特別,使用Windows安裝常常有一堆問題。
加上近來Bee被人問MPI相關,可是Bee完全沒有接觸過MPI。
在看過DLL相關的段落時,Bee就了解MPI是如何實現了。
其實MPI的實現,可以說是將DLL及相關資料送到遠端電腦去執行。不過還要查證一下。
也就是有實現DLL的作業系統,MPI就可以很容易實現了。之前還在想是有多難的技術呢!
作業系統中有許多很細微的動作,而嵌入式系統工程師要從MCU進步到使用PC這些動作還是要有所理解。
這本書補償了這個空隙。

但寫程式,每天都在用,卻沒有什麼人想了解。
可是在嵌入式系統,這是基本功,基本到被人忽略。
所以Bee可以了解到這本書名為何要取名為程式設計師的自我修養。
書上的系統是以PC作業系統為平台。不過我本來沒有多大興趣,結果一看就停不下來。
Bee沒有想到有書如此詳細解析Loader,library,DLL的格式,還可以修改。
其中在Linux的資料特別詳細,也難怪嵌入式系統使用PC幾乎只用Linux。
因為Windows上什麼也不公開。而嵌入式的環境又是如此特別,使用Windows安裝常常有一堆問題。
加上近來Bee被人問MPI相關,可是Bee完全沒有接觸過MPI。
在看過DLL相關的段落時,Bee就了解MPI是如何實現了。
其實MPI的實現,可以說是將DLL及相關資料送到遠端電腦去執行。不過還要查證一下。
也就是有實現DLL的作業系統,MPI就可以很容易實現了。之前還在想是有多難的技術呢!
作業系統中有許多很細微的動作,而嵌入式系統工程師要從MCU進步到使用PC這些動作還是要有所理解。
這本書補償了這個空隙。

讀書:早上3小時,完成一天工作
這是買其他書本順便買的。和許多勵志書一樣。
不過Bee很懶,常常只有一小段時間有點用。
現在則是因為一句有用的話,讓Bee很受用。其實Bee還沒看完書,但取得有用的話已經夠用了。
這句話就是
"永遠要想備用計劃"。
Bee發現這句話有三個義意。
1.不要放棄原本目標。
2.即使不成功,也會有所進度。
3.若是意外失敗,也會停止情緒化,馬上收集狀態,想下一個動作。
有多太次,心想的計劃失敗了,到最後什麼也沒有。這一直是Bee心中最大的魔障。
不管看了多少勵志書,仍是無效。結果一句話,一個簡單的意念,就可以解決了。
每個人勵志方式不同,還是要好好了解自己,才能不斷進步。

不過Bee很懶,常常只有一小段時間有點用。
現在則是因為一句有用的話,讓Bee很受用。其實Bee還沒看完書,但取得有用的話已經夠用了。
這句話就是
"永遠要想備用計劃"。
Bee發現這句話有三個義意。
1.不要放棄原本目標。
2.即使不成功,也會有所進度。
3.若是意外失敗,也會停止情緒化,馬上收集狀態,想下一個動作。
有多太次,心想的計劃失敗了,到最後什麼也沒有。這一直是Bee心中最大的魔障。
不管看了多少勵志書,仍是無效。結果一句話,一個簡單的意念,就可以解決了。
每個人勵志方式不同,還是要好好了解自己,才能不斷進步。

2010年5月7日 星期五
uCOS-II win32-port官方版本解析
根據之前追蹤的經驗,重點在於如何利用Windows的Thread。
看過之後,發現果然是官方版本,在管理CtxSW更符合CPU運作,只不過更符合單核心的context switch。難怪可以避免多核心衝突。
使用的Hook比較少,大部分在OSStartHighRdy()內做,這個也是不錯的點,也是只有呼叫一次,同在cpu_c.c內。
它一樣使用三種thread:
context switch一個,動作就是排程管理。
timer中斷。
一般工作。
有一點和Bee想的一樣,要將win32的thread handle於在stack上才好管理。這點有做到,所以不會引發其他問題。
唯一不同的是一般工作的thread一不小心退回到win32 thread下,有做task delect動作,有做好的收尾。
MCU的話,會抓stack底部資料產生return,就不知到那裏去了。要是stack有放一些可以產生中斷的特定資料才可以防好。
對於Bee來說,欠缺的功能就是外部中斷支援,以及PC console界面管理了。
PC console界面,可以參考以前的PC.c進行移植。
外部中斷就要仿照Timer做了。
看過之後,發現果然是官方版本,在管理CtxSW更符合CPU運作,只不過更符合單核心的context switch。難怪可以避免多核心衝突。
使用的Hook比較少,大部分在OSStartHighRdy()內做,這個也是不錯的點,也是只有呼叫一次,同在cpu_c.c內。
它一樣使用三種thread:
context switch一個,動作就是排程管理。
timer中斷。
一般工作。
有一點和Bee想的一樣,要將win32的thread handle於在stack上才好管理。這點有做到,所以不會引發其他問題。
唯一不同的是一般工作的thread一不小心退回到win32 thread下,有做task delect動作,有做好的收尾。
MCU的話,會抓stack底部資料產生return,就不知到那裏去了。要是stack有放一些可以產生中斷的特定資料才可以防好。
對於Bee來說,欠缺的功能就是外部中斷支援,以及PC console界面管理了。
PC console界面,可以參考以前的PC.c進行移植。
外部中斷就要仿照Timer做了。
2010年5月4日 星期二
如何讀書2:多看幾次
學會速讀後,所會面臨的問題是,快速掃瞄後,到底有沒有吸收到?
其實這個問題後來才發現根本不同擔心。因為在開始理解掃瞄到的資訊後,就會"自然感覺到"是不是要再看一遍。
這裡的"自然感覺到"就是在掃瞄完後產生的,關於這點,就是和之前讀書是不一樣的。
因為以聲音為了解依據的時候,會自然以為意念的傳達是依聲音為準。
轉到速讀後,才發現並不是,也不完全是影像,可以說是一種多次元的意念。
以前在聲音為理解的時代,讀書資訊是以一維的方式進行輸入。
在速讀的狀況下,讀書資訊是以二維的方式進行輸入。
但因為速讀有一招"倒向看"就是一種段落掃瞄方式,進行輸入,完全不照順序性。
所以在腦中要以超維度的方式才可以解析二維輸入的速讀資訊。
解析後的資料比較像全書被分解成一堆以2D圖片索引的心得資料。
說是"心得"也不為過,因為大部分較為無義意的句子皆不存在了。
而有資料無法連貫的地方,就是沒看懂的地方。
當心思回想書的內容,很快就可以知道那裏沒有連貫,自然就會回去再看一次。
不過只讀一次,只能認知其表面含義。
反正速讀一本書的時間不長,基於表面含義再去看一次,就可以再看到更深的意境。
有時是書的問題,就算多看幾次也是不清楚。
這時的多看幾次就會變成是多看幾本不同人寫的相同主題的書。
不同的人表達不同,就可以找到和自己背景相符合的表達,這樣就可以看懂了。
其實這個問題後來才發現根本不同擔心。因為在開始理解掃瞄到的資訊後,就會"自然感覺到"是不是要再看一遍。
這裡的"自然感覺到"就是在掃瞄完後產生的,關於這點,就是和之前讀書是不一樣的。
因為以聲音為了解依據的時候,會自然以為意念的傳達是依聲音為準。
轉到速讀後,才發現並不是,也不完全是影像,可以說是一種多次元的意念。
以前在聲音為理解的時代,讀書資訊是以一維的方式進行輸入。
在速讀的狀況下,讀書資訊是以二維的方式進行輸入。
但因為速讀有一招"倒向看"就是一種段落掃瞄方式,進行輸入,完全不照順序性。
所以在腦中要以超維度的方式才可以解析二維輸入的速讀資訊。
解析後的資料比較像全書被分解成一堆以2D圖片索引的心得資料。
說是"心得"也不為過,因為大部分較為無義意的句子皆不存在了。
而有資料無法連貫的地方,就是沒看懂的地方。
當心思回想書的內容,很快就可以知道那裏沒有連貫,自然就會回去再看一次。
不過只讀一次,只能認知其表面含義。
反正速讀一本書的時間不長,基於表面含義再去看一次,就可以再看到更深的意境。
有時是書的問題,就算多看幾次也是不清楚。
這時的多看幾次就會變成是多看幾本不同人寫的相同主題的書。
不同的人表達不同,就可以找到和自己背景相符合的表達,這樣就可以看懂了。
2010年4月28日 星期三
uCOS-II Win32 Port解析及改善 -- 4
將中斷改為其他程式觸發:
將中斷改由外部程式控制,其中Timer改為外部程式觸發可以改為可以”停格”的作業系統模擬,可以觀察各中斷程式是否有執行異常,或是驗證程式。結果如下:

改進資料傳輸:
資料傳輸功能主要是可以使uCOS-II可以模擬在大量資料輸入狀況下,測試程式是否正常,可以應用在有通信的狀況下,或有輸出入資料的狀況下,看程式對於資料處理的情況。也可以增加除錯的報告,將程式運作的各種狀況報告,增加對程式的除錯。實行則以選擇跨行程通信的方式來做,選擇使用Pipe。因為Pipe具有以下特性:
1. 在Windows及Linux皆可以使用,具有平台轉移性。
2. 以檔案呼叫方式做為資料傳輸的方式,容易理解函式的用法。
因為檔案呼叫也會停止Thread,故Pipe實現在uC/OS-II中亦要一個獨立Task才不會干擾到其他的Task。結果如下:

可以發現兩支應用程式的資料為完全一樣,證明有寫到uC/OS Win32 Port。而且可以設定在Server程式關閉時,Client端亦可同時關閉。
加入此功能可以實現以軟體模擬外部環境對uC/OS-II做輸出入測試。
其他問題及改善提議:
在Windows上模擬uC/OS仍和DOS上執行的uC/OS有些行為不同。
1. random()行為不一樣:每一個Thread都有自己的random()的變數,和DOS不同是共用,所以不用保護也可以正常使用。但各Task的random()產出的數列完全相同,在DOS則完全不同。使得Win32 port模擬結果和DOS不同。
2. Mutex功能使用後當機,經查原始碼,發現也是因為hTaskThread[]沒有同步更新造成。
若是將Win 32A PI Thread Handle放在TCB中管理也許可以解決,但要重新做核心除錯。其主要構想為:
1. 利用沒有用到的Stack做為Thread Handle存放地方,就可以經由TCB管理。而Stack在實體CPU會用到,但也不會亂改,所以是安全的。
2. 影響到函式有OSSchedulThread()及OSTCBInitHook()。
3. 需要修改的變數有二個hTaskThread[]及taskSuspended[]。
4. taskSuspended[]是管理task是可以執行或是不可執行flag。
hTaskThread[]是Win32API的Thread Handle。此二個變數要改用Stack做為存放的地方,故資料結構要做變動。
5. OSTCBInitHook()是向Win32API申請Thread Handle的函式,要改成Handle改存到pTcb->OSTCBStkPtr,taskSuspended[]標記亦一併存入。
6. OSSchedulThread()則要改成取用Handle時改由OSTCBCur->OSTCBStkPtr中取出Win32API Thread Handle,taskSuspended[]標記亦一併取出。
實作驗證是成功的。
後記:在要發表這篇時,將舊程式拿出來Run時,結果是當機的。原因在於Bee換了一台雙核電腦。也就是原先在單核心上是可以正常執行。
也因這個原因,改善的部分延至今日發表。
因為已經找到當機原因,且有在研究解決方法了。
所以就再次發表。後面會加上新的版本。
2010年4月13日 星期二
ION跑Folding@Home
反正Bee的ION小桌機從不關機,那就加跑一些公益軟體。
一般掛機只會用到CPU,所以Bee想利用一下GPU。
ION架Folding@Home無法簡單完成。
有幾件事要做的。
1.調整ION的記憶體大小,至可以使用GPU運算。
原設定為256MB,改到最大值512MB。這是因為256MB為顯示工作用,多的才是GPU運算用。
不調應是發不動。
2.修改FAH的參數。
因為認不出顯示卡型號,這點Bee是認為ION就是回傳"ION"導致無法比對出是那一等級的顯示卡。
所以就加入強制開啟的參數。 -forcegpu nvidia_g80

設定好了終於可以跑了。
結果幾乎呈現當機的Lag。
原來和電驢相衝。調整啟動順序,先開好其他程式,最後再開Folding@Home。這樣就行了。
還是有點Lag,但好多了。
看一下溫度,比平常多了十度。但電力好像沒有多多少。

跑一段時間,待螢幕進入休眠,馬上啟動GPU-Z則可以測到只多五度。
這應該算是用最少的電力跑Folding@Home了。
經過一天的測試,發現可能跑不及格。也就是可能三天算不完。最後還是放棄了。
一般掛機只會用到CPU,所以Bee想利用一下GPU。
ION架Folding@Home無法簡單完成。
有幾件事要做的。
1.調整ION的記憶體大小,至可以使用GPU運算。
原設定為256MB,改到最大值512MB。這是因為256MB為顯示工作用,多的才是GPU運算用。
不調應是發不動。
2.修改FAH的參數。
因為認不出顯示卡型號,這點Bee是認為ION就是回傳"ION"導致無法比對出是那一等級的顯示卡。
所以就加入強制開啟的參數。 -forcegpu nvidia_g80

設定好了終於可以跑了。
結果幾乎呈現當機的Lag。
原來和電驢相衝。調整啟動順序,先開好其他程式,最後再開Folding@Home。這樣就行了。
還是有點Lag,但好多了。
看一下溫度,比平常多了十度。但電力好像沒有多多少。

跑一段時間,待螢幕進入休眠,馬上啟動GPU-Z則可以測到只多五度。
這應該算是用最少的電力跑Folding@Home了。
經過一天的測試,發現可能跑不及格。也就是可能三天算不完。最後還是放棄了。
2010年4月6日 星期二
JAVA霸主地位不再
Bee常去看TIOBE的電腦語言排行。以了解電腦的走向。
這個月(2010/4)出現了令人意外的排名:JAVA不再是第一了。
而第一改為C語言。
不管如何,前二大語言的佔有率仍是沒有其他語言可以威脅的。
只是長期來看,用JAVA吃飯肯定比C來得難。

這個月(2010/4)出現了令人意外的排名:JAVA不再是第一了。
而第一改為C語言。
不管如何,前二大語言的佔有率仍是沒有其他語言可以威脅的。
只是長期來看,用JAVA吃飯肯定比C來得難。

2010年3月31日 星期三
工作流模式(workflow pattern)相關資料
為了找出並行計算上的各種狀況,需要找到可以表達的模型。
目前已知並行狀態機可以使用Petri Net來表達。
在找Petri Net資料中,找到了工作流模式(workflow pattern)。
也就是所有並行式工作流,都可以使用工作流模式內的模型來表達。
工作流模式基本模型有21種:
1. 順序(Sequence)
2. 平行拆分(Parallel Split)
3. 同步(Synchronization)
4. 排他選擇(Exclusive Choice)
5. 單合併(Single Merge)
6. 多選(Multi-choice)
7. 平行合併(Synchronize Merge)
8. 多合併(Multi-merge)
9. 鑒別器(Discriminator)
10. M中的N模式(N-out-of-M Join)
11. 強制循環(Arbitrary Cycles)
12. 隱式終止(Implicit Termination)
13. 非同步的多實例(Multiple Instances Without Synchronization)
14. 在設計期間預先確定的多實例(Multiple Instances With a Priori Design Time Knowledge)
15. 在運行期預先確定的多實例(Multiple Instances With a Priori Runtime Knowledge)
16. 無法在運行期預先確定的多實例(Multiple Instances Without a Priori Runtime Knowledge)
17. 延遲選擇(Deferred Choice)
18. 交替平行路由(Interleaved Parallel Routing)
19. 里程碑(Milestone)
20. 取消活動(Cancel Activity)
21. 取消實例(Cancel Case)
可以到
http://is.ieis.tue.nl/research/patterns/patterns.htm
上面有動畫實例,可以很容易的了解各模型的差異。
有了這個工作流模式,只要把各狀況找出解決方式,就不會用自己想的怪方法來解,然後遇到不明的問題。
目前已知並行狀態機可以使用Petri Net來表達。
在找Petri Net資料中,找到了工作流模式(workflow pattern)。
也就是所有並行式工作流,都可以使用工作流模式內的模型來表達。
工作流模式基本模型有21種:
1. 順序(Sequence)
2. 平行拆分(Parallel Split)
3. 同步(Synchronization)
4. 排他選擇(Exclusive Choice)
5. 單合併(Single Merge)
6. 多選(Multi-choice)
7. 平行合併(Synchronize Merge)
8. 多合併(Multi-merge)
9. 鑒別器(Discriminator)
10. M中的N模式(N-out-of-M Join)
11. 強制循環(Arbitrary Cycles)
12. 隱式終止(Implicit Termination)
13. 非同步的多實例(Multiple Instances Without Synchronization)
14. 在設計期間預先確定的多實例(Multiple Instances With a Priori Design Time Knowledge)
15. 在運行期預先確定的多實例(Multiple Instances With a Priori Runtime Knowledge)
16. 無法在運行期預先確定的多實例(Multiple Instances Without a Priori Runtime Knowledge)
17. 延遲選擇(Deferred Choice)
18. 交替平行路由(Interleaved Parallel Routing)
19. 里程碑(Milestone)
20. 取消活動(Cancel Activity)
21. 取消實例(Cancel Case)
可以到
http://is.ieis.tue.nl/research/patterns/patterns.htm
上面有動畫實例,可以很容易的了解各模型的差異。
有了這個工作流模式,只要把各狀況找出解決方式,就不會用自己想的怪方法來解,然後遇到不明的問題。
2010年3月30日 星期二




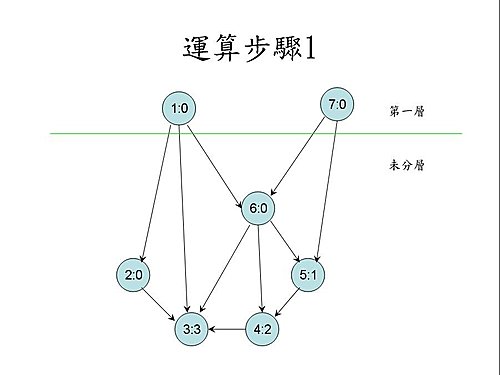


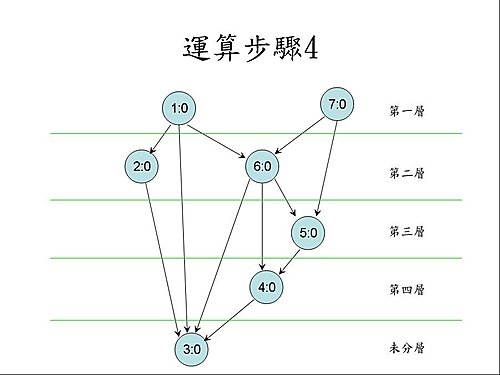

2010年3月16日 星期二
"多核計算與程式設計"介紹

1.讀書原由
在CUDA程式設計上面遇到許多多核心程式計算的問題。個人從單核心作業系統一下子變成多核心程式設計,才發覺對於多核心知識的不足。
而CPU多核心已流行數年,在新的PC硬體上,要使用雙核心已是基本配備。意指,多核心已經是免費午餐。
但在軟體設計上,卻很少使用到雙核心,甚至四核心來做為加速。為何會如此?轉換程式是如此慢,其原因為何?
在收集網路資料後發現,出在使用語言上的問題比作業系統支援多核心來得嚴重。但不管如何,中文資料一樣貧乏。
a.作業系統支援及其問題
過去:
作業系統支援多核心是最早的,在Unix作業系統就已發展出支援多核心的方式。
但是現代作業系統都有支援的狀況下,為何沒有什麼程式設計師願意使用?原因在於使用的門檻高,且其經濟效應不好。
因為多核心程式在單核心的CPU運行效率不好,在市場尚未普及前,多數工程師仍未接受多核心程式訓練。
現在:
但現在環境已經不同了,多核心時代真的到來。
b.電腦語言支援多核心問題
過去:
其實這才是目前多核心程式發展的最大阻礙。撰寫多核心程式只能使用作業系統支援的狀況下,困難度太高。
而大部分使用者所使用的語言皆為對於單核心所設計。能使用在多核心的電腦語言則是太少。
所以大部分程式設計仍然被單核心程式語言所限住。這才是多核心程式真正無法流行的原因。
因為程式語言就是要讓使用者方便處理設計,若是學習門檻太高,就不易推行。
現在:
語言延伸:MPI、OpenMP
平行語言:Erlang、Scala
c.使用CUDA之後才發現的問題
CUDA的推行以資料為主的平行計算。和之前在作業系統所提的工作為主的平行計算上有很大的不同。
在超過八核心同時運算時,為了要增加產出率,勢必要採行以SIMD為主的語言架構,也就是資料為主的程式概念。
但個人發現,可以找到的資料不多,所以轉以找多核心程式的資料,所以找到此書。
2.書本結構
a.基礎知識
多核計算概述
多線程編程基礎
OpenMP程式設計
b.基礎資料結構及算法
結構
Link List
Hash
Tree
AVL search tree
c.平行運算法
並行程式設計模式
並行搜尋
並行排序
並行數值計算
d.共享資源分散式計算
分散式計算設計模式
分散式陣列
分散式查找
分散式記憶體管理
e.任務分解及調度
任務圖分解及調度
動態任務分解及調度
Lock-Free編程基礎
3.比對CUDA
a.有許多問題是一樣的
b.CUDA中有些問題解法未表明產生原因,在多核心中則有解釋
c.CUDA可視為多核心的一種實現
d.可以有效利用CUDA中的原子函式
e.免除遇到多核心問題,無從看出問題產生原因
2010年2月20日 星期六
8051簡單多工7:堆疊(stack)使用狀況
發現忘了說使用這個架構是為了什麼。當然是省記憶體,但到底是省到那一種。答案是我想省下使用8051 Register file。
有玩8051的應該會知道8051產生副程式呼叫所使用的堆疊在那裏,就是Registers file。問題是它的大小只有256byte。
也就是說,最大只能呼叫128層的副程式,還要扣除使用暫存器、中斷程式的使用,實際上連100層都到不了。
當堆疊玩爆了,什麼怪現象都會冒出來,沒有對處理器了解的人,是永遠也不知問題出在那裡。
可是有人會問,是誰有辦法寫出40層以上的呼叫,玩到堆疊爆掉。其實也不用那麼多層也可以爆掉的。
在函式內的區域變數也是在用堆疊的,也就是如果函式內皆使用30byte的區域變數,呼叫個十層,就會爆了。
可是有人會問,他寫8051程式已經很大了,並沒有遇到我說的現象。這就是Compiler的工作了,像Keil C在每次函式呼叫,會去計算使用多少堆疊。所以可以預測是否出現堆疊爆掉的狀況。
不過中斷程式也是使用堆疊,卻不在計算範圍內,所以有時中斷程式寫太大仍會發生怪現象。
好了,談了這麼多,和多工有何關係?
當然有,因為多工,所以函式的數量一定大增,以RTOS來寫,每一個Task都會要求獨立的堆疊,8051的堆疊根本不夠用。
不過8051上仍有RTOS,像uCOS就有8051版本,只不過它在切換Task時,是將整個Stack都搬到外部記憶體去,然後又從外部記憶體搬另一個Task的回來。這樣做其實效率並不好,但也只能接受。因為8051原設計就沒想到裝作業系統這樣東西進去。
而Bee在設計上,有想到保留堆疊(stack),所以採用非強制多工的方法,如此一來就可以確定函式執行完成退出後,才會輪到另一個task的函式執行。這就是一開始設計上的考量。
不過有所犧牲,程式只能以狀態機的方式寫,會使得別人不好閱讀程式。
不過Task之間因為要回到main()中才能切換,回到main()即表示全部堆疊都已釋放,也就是Task之間不會有堆疊互相堆積的問題。也就可以確保每個Task都幾乎有完整的8051堆疊可用。
這是這個架構的好處,在實際使用上,就有許多變數可以放進Register file可以增加8051的運作速度了。或者可以使用比較多層的中斷程式也比較不用擔心。
但這個架構仍有一個問題,那就是Keil C因為會去預測堆疊的使用。當安排一個Task是由一群循環的狀態函式所組成時,Keil C會提出使用到遞迴結構的警告。這個我還不知要如何去除。看看那天能有人給點建議。
不過只是警告,還不至於影響執行。
Bee實作上,有遇到一次的是,單一的Task掛了,產生資料存取錯誤,另三個Task仍很正常。大概是沒有影響到全域變數,所以還好。可見穩定性還可以。
至於是那一個事件,可以去另一篇LCM當機解法看看。
有玩8051的應該會知道8051產生副程式呼叫所使用的堆疊在那裏,就是Registers file。問題是它的大小只有256byte。
也就是說,最大只能呼叫128層的副程式,還要扣除使用暫存器、中斷程式的使用,實際上連100層都到不了。
當堆疊玩爆了,什麼怪現象都會冒出來,沒有對處理器了解的人,是永遠也不知問題出在那裡。
可是有人會問,是誰有辦法寫出40層以上的呼叫,玩到堆疊爆掉。其實也不用那麼多層也可以爆掉的。
在函式內的區域變數也是在用堆疊的,也就是如果函式內皆使用30byte的區域變數,呼叫個十層,就會爆了。
可是有人會問,他寫8051程式已經很大了,並沒有遇到我說的現象。這就是Compiler的工作了,像Keil C在每次函式呼叫,會去計算使用多少堆疊。所以可以預測是否出現堆疊爆掉的狀況。
不過中斷程式也是使用堆疊,卻不在計算範圍內,所以有時中斷程式寫太大仍會發生怪現象。
好了,談了這麼多,和多工有何關係?
當然有,因為多工,所以函式的數量一定大增,以RTOS來寫,每一個Task都會要求獨立的堆疊,8051的堆疊根本不夠用。
不過8051上仍有RTOS,像uCOS就有8051版本,只不過它在切換Task時,是將整個Stack都搬到外部記憶體去,然後又從外部記憶體搬另一個Task的回來。這樣做其實效率並不好,但也只能接受。因為8051原設計就沒想到裝作業系統這樣東西進去。
而Bee在設計上,有想到保留堆疊(stack),所以採用非強制多工的方法,如此一來就可以確定函式執行完成退出後,才會輪到另一個task的函式執行。這就是一開始設計上的考量。
不過有所犧牲,程式只能以狀態機的方式寫,會使得別人不好閱讀程式。
不過Task之間因為要回到main()中才能切換,回到main()即表示全部堆疊都已釋放,也就是Task之間不會有堆疊互相堆積的問題。也就可以確保每個Task都幾乎有完整的8051堆疊可用。
這是這個架構的好處,在實際使用上,就有許多變數可以放進Register file可以增加8051的運作速度了。或者可以使用比較多層的中斷程式也比較不用擔心。
但這個架構仍有一個問題,那就是Keil C因為會去預測堆疊的使用。當安排一個Task是由一群循環的狀態函式所組成時,Keil C會提出使用到遞迴結構的警告。這個我還不知要如何去除。看看那天能有人給點建議。
不過只是警告,還不至於影響執行。
Bee實作上,有遇到一次的是,單一的Task掛了,產生資料存取錯誤,另三個Task仍很正常。大概是沒有影響到全域變數,所以還好。可見穩定性還可以。
至於是那一個事件,可以去另一篇LCM當機解法看看。
2010年2月18日 星期四
8051簡單多工6:核心編譯之組語
這篇是給慣用組合語言的人做為比較的,並且看看8051是如何去做函式指標呼叫。
我使用SDCC的組譯程式來看,因為Keil c的比較複雜。以下為main()中程式轉成組合語言段落:
C語言部分:前面數字為行號,可以在組合語言中找到對應段落。TASK_NUM設為4
77:void main(void)
78:{
79: PCA0MD &= ~0x40; // Disable Watchdog timer
80: Init_Device();
81: while (1)
82: {
83: register void (*Current_Func)(void);
84: EA = 0;
85: Current_Func = TaskFunc[FuncID]; // may break with interrupt
86: EA = 1;
87: Current_Func();
88: FuncID = (++FuncID) % TASK_NUM;
89: }
90:}
ASM組合語言結果:
;------------------------------------------------------------
;Allocation info for local variables in function 'main'
;------------------------------------------------------------
;Current_Func Allocated to registers r2 r3
; main.c 77
; -----------------------------------------
; function main
; -----------------------------------------
_main:
; main.c 79
anl _PCA0MD,#0xBF
; main.c 80
lcall _Init_Device
; main.c 81
00102$:
; main.c 84
clr _EA
; main.c 85
mov r0,#_FuncID
mov a,@r0
add a,acc
; Peephole 105 removed redundant mov
mov r2,a
add a,#_TaskFunc
mov r0,a
mov ar2,@r0
inc r0
mov ar3,@r0
dec r0
; main.c 86
setb _EA
; main.c 87
mov a,#00107$
push acc
mov a,#(00107$ >> 8)
push acc
push ar2
push ar3
ret
00107$:
; main.c 88
mov r0,#_FuncID
mov a,#0x01
add a,@r0
mov r2,a
mov r0,#_FuncID
mov b,#0x04
mov a,r2
div ab
mov @r0,b
; Peephole 132 changed ljmp to sjmp
sjmp 00102$
00104$:
ret
可以看到Current_Func是使用r2及r3暫存器。
取函式指標執行是第87行的動作,使用四個push及一個ret來做,這不是一般人可以理解的吧。Keil C呼叫更多東西。
唯一可以確定的是push ar2及puah ar3中的ar2及ar3就是暫存器r2及r3。
從這裏可以看到除餘(%)真的是拿去除,所以上一篇才會提到加速及展開的問題。不過Keil C就聰明多了,會用and 3去做。
要玩MCU還是要看一下組合語言在幹什麼,常常和想的不同。
我使用SDCC的組譯程式來看,因為Keil c的比較複雜。以下為main()中程式轉成組合語言段落:
C語言部分:前面數字為行號,可以在組合語言中找到對應段落。TASK_NUM設為4
77:void main(void)
78:{
79: PCA0MD &= ~0x40; // Disable Watchdog timer
80: Init_Device();
81: while (1)
82: {
83: register void (*Current_Func)(void);
84: EA = 0;
85: Current_Func = TaskFunc[FuncID]; // may break with interrupt
86: EA = 1;
87: Current_Func();
88: FuncID = (++FuncID) % TASK_NUM;
89: }
90:}
ASM組合語言結果:
;------------------------------------------------------------
;Allocation info for local variables in function 'main'
;------------------------------------------------------------
;Current_Func Allocated to registers r2 r3
; main.c 77
; -----------------------------------------
; function main
; -----------------------------------------
_main:
; main.c 79
anl _PCA0MD,#0xBF
; main.c 80
lcall _Init_Device
; main.c 81
00102$:
; main.c 84
clr _EA
; main.c 85
mov r0,#_FuncID
mov a,@r0
add a,acc
; Peephole 105 removed redundant mov
mov r2,a
add a,#_TaskFunc
mov r0,a
mov ar2,@r0
inc r0
mov ar3,@r0
dec r0
; main.c 86
setb _EA
; main.c 87
mov a,#00107$
push acc
mov a,#(00107$ >> 8)
push acc
push ar2
push ar3
ret
00107$:
; main.c 88
mov r0,#_FuncID
mov a,#0x01
add a,@r0
mov r2,a
mov r0,#_FuncID
mov b,#0x04
mov a,r2
div ab
mov @r0,b
; Peephole 132 changed ljmp to sjmp
sjmp 00102$
00104$:
ret
可以看到Current_Func是使用r2及r3暫存器。
取函式指標執行是第87行的動作,使用四個push及一個ret來做,這不是一般人可以理解的吧。Keil C呼叫更多東西。
唯一可以確定的是push ar2及puah ar3中的ar2及ar3就是暫存器r2及r3。
從這裏可以看到除餘(%)真的是拿去除,所以上一篇才會提到加速及展開的問題。不過Keil C就聰明多了,會用and 3去做。
要玩MCU還是要看一下組合語言在幹什麼,常常和想的不同。
8051簡單多工5:使用上的調整及範例
編譯環境差異:
目前在Keil c及SDCC下編譯皆有過。但Bee沒有使用SDCC實際去執行過。不過SDCC編出來的組合語言看來沒有問題,應是可以用的。
核心加速:
在看編出來的組合語言,可以發現Bee使用除餘(%)來做FuncID調整會動用到除法,使執行效率下降。
比較好的寫法是將FuncID整個展開,這樣也不用去計算它。
以使用三個Task為例,將while改寫為:
while (1)
{
TaskID = 0;
EA = 0;
Current_Func = TaskFunc[TaskID];
EA = 1;
Current_Func();
TaskID++;
EA = 0;
Current_Func = TaskFunc[TaskID];
EA = 1;
Current_Func();
TaskID++;
EA = 0;
Current_Func = TaskFunc[TaskID];
EA = 1;
Current_Func();
}
這樣執行起來更有效率。
另一個例子:
這是Key Scan範例
// Key Scan function
#define KEY_SCAN_DELAY 1 // 1ms
void key_scan2(void);
void key_scan3(void);
void key_scan4(void);
void key_Encode(void);
unsigned char KeyScan[5]; // unknow why KeyScan[0] can't be used? just skip
void key_scan1(void)
{
KeyScan[4] = P1;
P1 = ~(1<<0)<<4 | 0x0F;
Task_Delay_Next(key_scan2);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
void key_scan2(void)
{
KeyScan[1] = P1;
P1 = ~(1<<1)<<4 | 0x0F;
Task_Delay_Next(key_scan3);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
void key_scan3(void)
{
KeyScan[2] = P1;
P1 = ~(1<<2)<<4 | 0x0F;
Task_Delay_Next(key_scan4);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
void key_scan4(void)
{
KeyScan[3] = P1;
P1 = ~(1<<3)<<4 | 0x0F;
Task_Set_Next(key_Encode);
}
// Encode Key code
void key_Encode(void)
{
// do some thing here
Task_Delay_Next(key_scan1);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
// Key Scan function end
比較一下使用uCOS的寫法
void key_scan(void)
{
while(1)
{
KeyScan[4] = P1;
P1 = ~(1<<0)<<4 | 0x0F;
OSTimeDly(10);
KeyScan[1] = P1;
P1 = ~(1<<1)<<4 | 0x0F;
OSTimeDly(10);
KeyScan[2] = P1;
P1 = ~(1<<2)<<4 | 0x0F;
OSTimeDly(10);
KeyScan[3] = P1;
P1 = ~(1<<3)<<4 | 0x0F;
// do something here
OSTimeDly(10);
}
}
可以發現這個簡單多工是以狀態機的方式下去寫,就是以一個狀態的函式再跳到另一個狀態的函式的寫法。
而uCOS在執行OSTimeDly()之後可以再從它的下一行執行下去。這個是比較容易理解的寫法。
不過8051的資源不多,Bee才會自創多工核心。
目前在Keil c及SDCC下編譯皆有過。但Bee沒有使用SDCC實際去執行過。不過SDCC編出來的組合語言看來沒有問題,應是可以用的。
核心加速:
在看編出來的組合語言,可以發現Bee使用除餘(%)來做FuncID調整會動用到除法,使執行效率下降。
比較好的寫法是將FuncID整個展開,這樣也不用去計算它。
以使用三個Task為例,將while改寫為:
while (1)
{
TaskID = 0;
EA = 0;
Current_Func = TaskFunc[TaskID];
EA = 1;
Current_Func();
TaskID++;
EA = 0;
Current_Func = TaskFunc[TaskID];
EA = 1;
Current_Func();
TaskID++;
EA = 0;
Current_Func = TaskFunc[TaskID];
EA = 1;
Current_Func();
}
這樣執行起來更有效率。
另一個例子:
這是Key Scan範例
// Key Scan function
#define KEY_SCAN_DELAY 1 // 1ms
void key_scan2(void);
void key_scan3(void);
void key_scan4(void);
void key_Encode(void);
unsigned char KeyScan[5]; // unknow why KeyScan[0] can't be used? just skip
void key_scan1(void)
{
KeyScan[4] = P1;
P1 = ~(1<<0)<<4 | 0x0F;
Task_Delay_Next(key_scan2);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
void key_scan2(void)
{
KeyScan[1] = P1;
P1 = ~(1<<1)<<4 | 0x0F;
Task_Delay_Next(key_scan3);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
void key_scan3(void)
{
KeyScan[2] = P1;
P1 = ~(1<<2)<<4 | 0x0F;
Task_Delay_Next(key_scan4);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
void key_scan4(void)
{
KeyScan[3] = P1;
P1 = ~(1<<3)<<4 | 0x0F;
Task_Set_Next(key_Encode);
}
// Encode Key code
void key_Encode(void)
{
// do some thing here
Task_Delay_Next(key_scan1);
Task_Delay_Ms(KEY_SCAN_DELAY);
}
// Key Scan function end
比較一下使用uCOS的寫法
void key_scan(void)
{
while(1)
{
KeyScan[4] = P1;
P1 = ~(1<<0)<<4 | 0x0F;
OSTimeDly(10);
KeyScan[1] = P1;
P1 = ~(1<<1)<<4 | 0x0F;
OSTimeDly(10);
KeyScan[2] = P1;
P1 = ~(1<<2)<<4 | 0x0F;
OSTimeDly(10);
KeyScan[3] = P1;
P1 = ~(1<<3)<<4 | 0x0F;
// do something here
OSTimeDly(10);
}
}
可以發現這個簡單多工是以狀態機的方式下去寫,就是以一個狀態的函式再跳到另一個狀態的函式的寫法。
而uCOS在執行OSTimeDly()之後可以再從它的下一行執行下去。這個是比較容易理解的寫法。
不過8051的資源不多,Bee才會自創多工核心。
訂閱:
意見 (Atom)